Private GPT
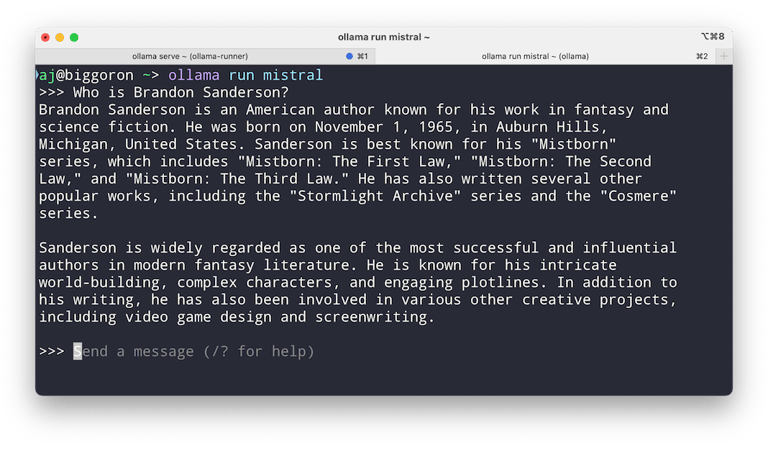
Everyone uses AI and LLMs, but do you trust them with your data? Well, no worries! You can run an LLM locally on your machine and access the most recent models using Ollama.
It should automatically detect your GPU and run the model on it, but sometimes it defaults to the CPU if your GPU isn't supported (like mine), which can lead to longer response times.
In my case, I have an Intel i5-12400 CPU running at 4.4GHz, so the response time wasn't that bad, but I really wanted it to run on my RX 6700 XT GPU. I found an article that helped me acheive that.
Finally, as cool as it is to run an LLM in the terminal, I wanted a ChatGPT-like UI. I found a very cool project that provides exactly that.
My AMD GPU was horrible driver wise for AI work so I ended up buying an Nvidia GPU : RTX 4070 TI SUPER. There was clearly a huge difference in performance and drievr compatibility allowing me to do much more.
I installed ComfyUI and started working with it. It allows running local image generation models locally : text to image, text to video, image to video, image to image... and I linked it to my open-webui app.
I then installed N8N locally which is a powerful tool to automate workflows. I used it to create AI agents starting with a RAG (Retrieval-augmented generation) which is a way of feeding knowledge to an already trained LLM by transforming text extracted from documents and transform it to vectors (using embedding models) that can be stored in a vector database for AI (I use Qdrant)
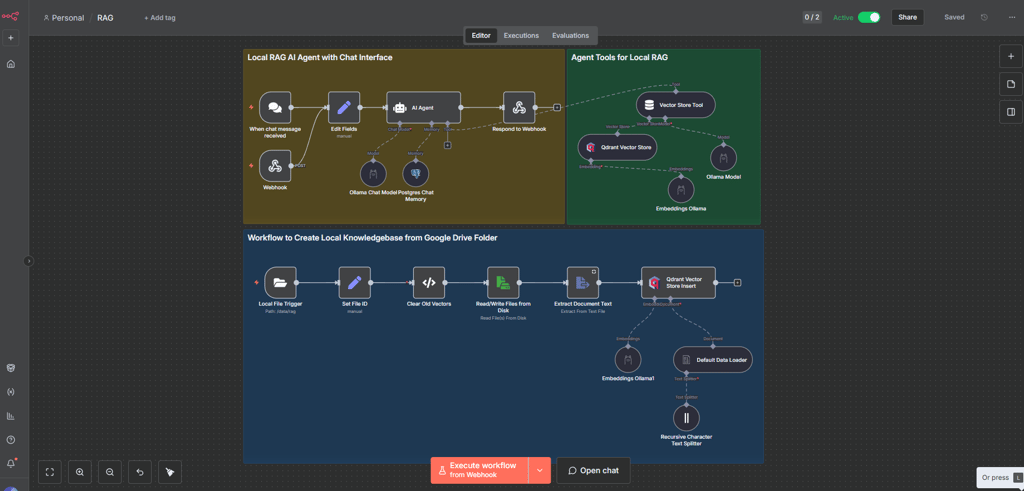
I integrated this into Open webui but recent versions allowed to do this directly in admin panel. But I still use N8N for other agentic AI work I really recommend it.
The pile is starting to add up so I switched to docker and now I run each service in a seperate docker container all orchastrated with a docker-compose.
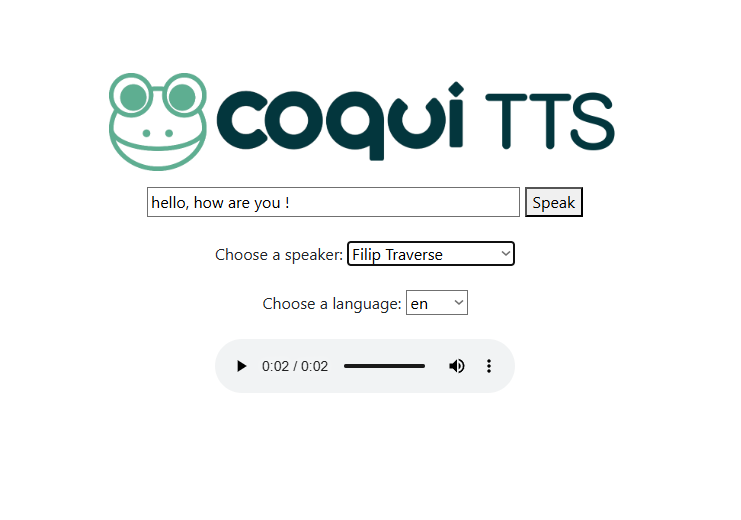
I wanted to add a local STT (speach to text) and TTS (text to speech) models to my stack. For STT I used Whisper which is a powerful open source model created by openai and again I integrated it with open-webui.
For the TTS it was a bit more complicated as there are a lot of models and they all work differently depending on the languages supported and the voices we want. I wanted PERFORMANCE, so I chose coqui-tts with their largest model "tts_models/multilingual/multi-dataset/xtts_v2". I had to edit their source code a little for it to work as it operates a bit diffrently from the other models. I wanted a seperate interface for it so I can work with it in a way similar to ElevenLabs. The model uses the GPU of course for faster and better responses.